
 登錄
登錄
 注冊
注冊
中美兩位AI大師的“巔峰對話”:為何NLP領域難以出現“獨角獸”?

2017 年,人工智能領域迎來了轉折之年:在這一年,傳統的計算機視覺和語音識別都達到了新的高度,也在性能方面趨于飽和 。在 2017 年的 ImageNet 圖片識別比賽中,參賽的 38 支隊伍中有 29 支錯誤率低于 5%(2011年,表現最好的隊伍也有四分之一左右的錯誤率)。部分由于這個原因,ImageNet 宣布將在 2018 年改變數據集,增加難度。
在產業方面,不少專注于計算機視覺的公司也獲得了長足發展。其中比較具有代表性的是估值已經超過 20 億美元的商湯科技,在經歷了數輪大額融資之后,其隱隱有從獨角獸變成巨頭的趨勢。
不過,人工智能另一個相關領域自然語言處理 似乎沒有達到這種高度。在技術方面,這一領域的技術準確率遠遠沒有達到計算機視覺和語音識別的水平,技術產品(比如個人助手)經常被人諷刺只能用來調戲,缺少實際價值。在創業公司方面,自然語言處理領域也沒有產生像商湯、曠視、依圖、云從這樣的“小巨頭” 。
這些現狀都恰恰說明自然語言處理的難度。然而,可以說這項技術有多難,就有多重要。
微軟創始人比爾·蓋茨曾經表示,“語言理解是人工智能領域皇冠上的明珠”。微軟全球執行副總裁沈向洋也在2017年底的公開演講時說:“懂語言者得天下……下一個十年,人工智能的突破在自然語言的理解 ……人工智能對人類影響最為深刻的就是自然語言方面”。
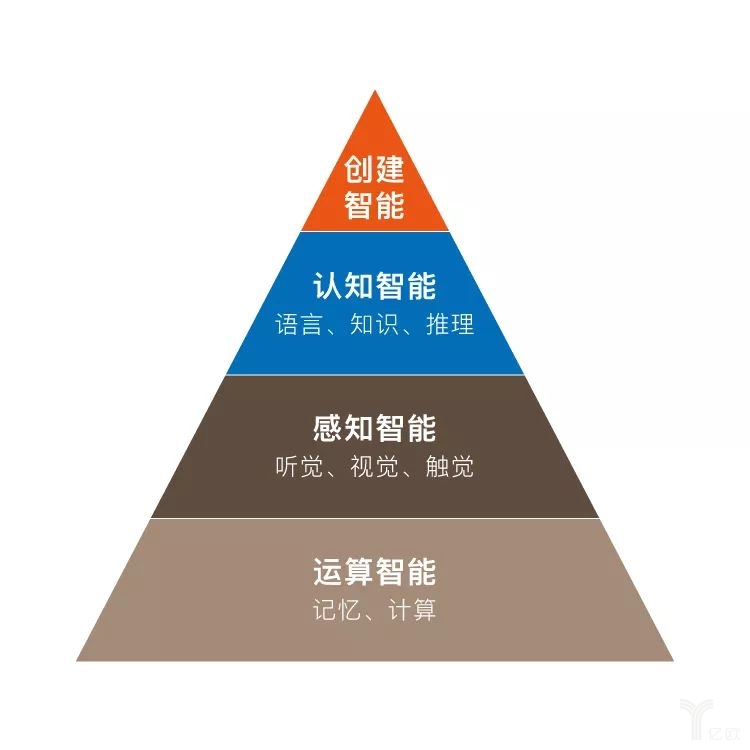
人工智能包括兩個重要的部分——“感知”和“認知”。其中,計算機視覺和語音識別等領域屬于感知部分,而自然語言處理屬于認知部分的重要內容。對一個“智能”而言,僅僅感知當然不夠,理解和消化內容的認知能力才是真正意義上的核心。
那么,我們究竟何時才能摘下這個“人工智能領域皇冠上的明珠”?圍繞這個問題,近日,記者分別采訪了兩位自然語言處理領域的領軍人物:賓夕法尼亞大學教授 Dan Roth 和微軟亞洲研究院副院長周明。
對于自然語言處理領域的從業者來說,這兩位的名聲如雷貫耳。

Dan Roth 教授致力于通過機器學習和推理的方法幫助機器理解自然語言,他也是 AAAS、ACL、AAAI 和 ACM 的會士,曾在多個重要會議上擔任程序主席一職,他也是中國計算機學會主辦的國際自然語言處理和中文計算大會(NLPCC2018)的大會主席之一。

而周明博士作為中國自然語言處理最頂尖的學者之一,目前擔任微軟亞洲研究院副院長、國際計算語言學協會(ACL)候任主席、中國計算機學會理事、中文信息技術專委會主任、術語工作委員會主任、中國中文信息學會常務理事等多個職務,還是哈爾濱工業大學、天津大學、南開大學、山東大學等多所學校博士導師。
在與兩位 NLP 領軍人物的對話中,DT君發現,兩位受訪者在一些熱門話題上有所分歧,比如說近幾年愈發火熱的專業競賽, Dan Roth 認為這樣的競賽長期來看對推動科學研究和發展價值不大,而周明的看法則正面得多。而在比較自然語言處理和計算機視覺的發展時,兩位都認為,自然語言處理遠比計算機視覺復雜,仍有許多問題沒有解決。
盡管如此,在訪談的最后,Dan Roth 和周明也都表示出對于自然語言處理有望在 2018 年涌現新進展的信心 。以下為訪談全文:
我們還沒看到非常大的 NLP 創業公司
問:為什么自然語言處理領域沒有產生非常大的創業公司?
周明 :
這個問題很值得研究。總的來說,這是因為自然語言處理的技術難度太大,和應用場景太復雜。
一個公司的成立和發展是由需求驅動。圖像識別的需求巨大,例如安防和身份認證的應用場景很多,到處都有攝像頭,誰也看不過來。所以,安防領域一直期待著一種技術,只要達到一個閾值,立刻就能用了,恰好這兩年深度學習把計算機視覺水平升到了那個閾值。此外,就像上面的回答所說,圖像識別問題更干凈,再加上有現成且巨大的場景。所以,只要技術有一點突破,場景自然結合,公司一下子就做起來。
特別純粹的自然語言應用(不包括搜索),主要就是機器翻譯。機器翻譯長期有需求,但沒有安防和身份認證的需求那么大。而且,機器翻譯水平一直不到位。即使到今天,機器也很難翻譯有背景的復雜句子。
另外,自然語言處理的應用太依賴于UI了。圖像識別基本不需要UI,直接在系統內部集成一些技術就行。包括微軟在內的所有公司做翻譯軟件,如果UI做得不行,用戶體驗不行,人們就不會愿意使用。
技術產業化最重要的是商業模式,也就是怎么讓技術掙錢。圖像識別公司的掙錢模式已經成立了,但翻譯付費就難多了。所以自然語言是從研究到技術到落地到商業化,面臨一系列的挑戰。
目前的現狀是,自然語言處理技術更多的是作為公司內部技術,比如內部的商業情報或人機接口功能。但這不代表我們未來找不到這樣的渠道。
Dan Roth :
在各種專業應用中,必須要選擇正確的自然語言模型,沒有任何單一模型可以解決自然語言領域中所遇到的所有問題,自然語言處理沒有一個可以解決所有問題的魔術盒子存在,你必須要把所有相關的知識庫放進盒子里,選擇對的算法,并且針對性的處理特定問題,那么這個盒子最后才有作用。這種現狀加大了技術落地的難度。
舉例來說,計算機視覺發展到最后已經不是只有單純識別圖像或者是物體,而是要能夠做到預測這些物體的本身的下一個動作,比如說在桌子上放了瓶水,然后把瓶子往外推,一個先進的計算機視覺系統就能夠判斷出瓶子最終的動作軌跡可能是掉到桌子下。然而自然語言處理技術達不到這種水平,它無法進行預測。它只能就現有的文字組合、數據庫來判斷所有文字應該有的意義。
計算機視覺的物體識別準確度已經可以達到將近百分之百,而自然語言目前的閱讀準確度也不過將近9成,而這也是目前自然語言處理商用化的最大阻礙。如果要用到專業領域,那么現有的精準度明顯不足。
即使我們不考慮基礎研究的困難,就算是現有的自然語言處理的基礎研究結果,似乎也沒有很好地轉化,很多產品在發布會上的效果往往和實際使用的效果完全不同。
周明 :
目前自然語言處理產品出現的問題,很多時候無關技術,而是在產品設計和UI方面做得不夠好。
在做機器閱讀理解和機器翻譯研究的時候,我們往往有一個固定的評測集,以及F-分數和精確度這樣的評測方法。但這些不代表用戶的體驗,即使在實驗中分數達到100%也是這樣。技術是獨立于產品應用方向發展的,做產品的人應用技術的時候要運用之妙存乎一心。他們要考慮,無論是78%的技術,還是88%或者98%的技術,要怎么運用到產品里,才能讓用戶體驗最好。
用戶體驗要考慮什么呢?最重要的是用戶界面。因為系統很難達到100%的正確,所以要考慮用戶怎么操作,怎么容錯,讓他們接受有缺陷的結果。比如說搜索引擎返回多個搜索結果的設計,其實非常巧妙。因為誰都知道搜索達不到那么好的水準,但當返回多個結果后,用戶不抱怨搜索引擎,反而認為搜索引擎的結果擴大了他的思路,把壞事變成好事。
這種巧妙的用戶界面設計和用戶體驗設計,是做自然語言處理的人要好好考慮的。系統和研究厲害,不代表能把用戶體驗做好。要從用戶的角度看,如何把你的技術,融入到其他所有的相關的場景中,解決用戶的實際問題。
還是以機器翻譯為例,在實驗室里,所有話都實驗了很多遍,也沒有什么噪聲,效果肯定很好。但做產品的時候要考慮語音、環境噪聲、背景噪聲、遠場識別、專有名詞,以及口音等等。如果做不好,會導致翻譯結果一塌糊涂。
但是,背景噪聲怎么來解決呢?首先要好好調整UI,要解決語音識別的一些問題,然后可能要解決簡單的多輪對話的問題,要對用戶口音做自動調整,如果用戶覺得翻譯不好,要有方便的方式和他們互動。這樣就能讓用戶覺得,這個系統雖然沒有那么好,但是他也給我解決了很多問題了。這一塊就是要考慮設計水平的能力了。
所以,這個不是科技要解決的問題,這個是產品設計要解決的問題。
2018年,我們可以期待哪些的 NLP 進展?
問:除了這些難點和問題,自然語言處理技術在研究和應用方面,可以在今年或未來幾年出現較大的進展?
Dan Roth :
利用知識庫,未來自然語言處理應用會協助企業把專業知識轉成特定的自然語言處理模型。利用這些模型,自然語言處理技術就能成為很好的工具,影響更深層次的人類生活。
周明 :
垂直領域有一定的保護門檻(比如有一些不公開的數據),導致大公司無法直接進入。在這樣的領域可以做一些知識圖譜的探索,還可以針對本領域特點,做一些特殊的優化和有的放矢的研究,而不是使用通用的自然語言技術。這樣就可能會產生一個專業的知識圖譜,以及基于專用圖譜之上的自然語言理解的技術。最后提升整個領域的生產力。
此外,神經網絡機器翻譯、閱讀理解、聊天對話,和創作輔助這四個應用在今年和明年就會有很多地方普及,相關的應用場景包括搜索引擎、個人助手、語音助手、機器翻譯,還有個人制作音樂,個人制作新聞、撰寫網絡小說、問答系統等等。
另外一個重要的應用是機器客服。一般沒人愿意看產品手冊,但如果讓計算機讀一遍產品手冊,你就能問它任何手冊里出現過的產品問題,就能在客服、售后服務這些領域產生很好的應用。智能客服可以幫助提高效率,節省人員。系統也可以按照座席收費,有商業模式。
對成熟公司來說,首先搜索引擎還有進步空間。如果搜索引擎有閱讀理解的能力,在手機屏幕上返回的結果特別精準,會產生很大的競爭優勢。第二,現在信息流非常重要。例如今日頭條背后的推薦技術需要理解文本,理解用戶,然后匹配他們。如果我們的自然語言處理能力提高了以后,推薦水平就提高了。
對創業公司來說,第一個機會是機器翻譯,但是要把用戶體驗和商業模式做好。第二個機會是客服。最后一個是開發垂直行業的自然語言處理技術。
“自然語言處理遠比計算機視覺復雜”
問:和一般的機器學習、人工智能領域以及機器視覺這樣的方向相比,自然語言處理領域是否有存在屬于自己的獨特挑戰,有什么解決方案?
Dan Roth :
計算機視覺基本上就是物體探測。雖然計算機視覺應用很多,但基本上核心算法都離不開物體探測這個方向,背后使用的邏輯也相當一致。
此外,由于計算機視覺的技術成熟度已經達到商用化的標準,所以我們可以看到很多不同的公司百花齊放。但自然語言處理的情況完全不同。不同場景、不同語言,甚至不同專業所需要用到的自然語言處理層次都不同,所以自然語言處理遠比計算機視覺復雜,且目前的應用還是相當少,要為了這些少數應用而開發自己的算法并不劃算。
周明 :
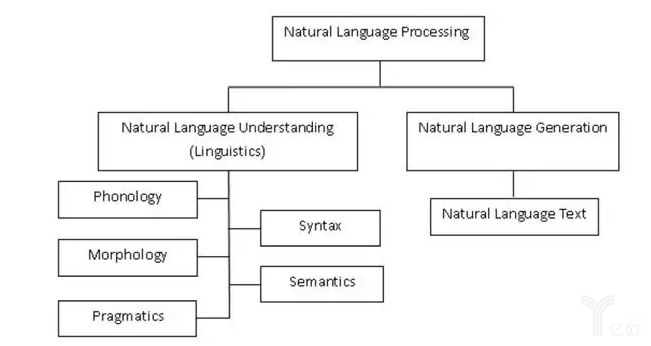
語音識別和圖像識別都是一輸入一輸出,問題非常干凈、簡潔。比如輸入一個圖片,要判斷里面有沒有花或者草,直接判斷就行了。這些方向中間沒有多輪,不需要交互,一般不太依賴于知識圖譜和常識,即使用也被證明沒有什么太大效果。
但自然語言處理有三個重要的區別,讓它變得很難:
第一,自然語言是多輪的,一個句子不能孤立的地看,要么有上下文,要么有前后輪對話。目前的深度學習技術,在建模多輪和上下文的時候,難度遠遠超過了一輸入一輸出的問題。所以語音識別做的好的人和圖像識別做的好的人,不一定能做好自然語言。
第二,自然語言除了多輪特征之外,它還涉及到了背景知識和常識知識,這個也是目前大家不清楚怎么建模,都沒有完全明白。
第三,自然語言處理要面對個性化問題。同樣一句話,不同的人用不同的說法和不同的表達,圖像一般沒有這么多變化。這種個性化、多樣化的問題非常難以解決。
因為人工智能包括感知智能(比如圖像識別、語言識別和手勢識別等)和認知智能(主要是語言理解知識和推理),而語言在認知智能起到最核心的作用。所以,我們可以很自信地說,如果我們把這些問題都解決了,人工智能最難的部分就基本上要解決了。
問:那怎么解決這些問題呢?
周明 :
雖然不保證可以改進技術,但有三個值得嘗試的方向:
第一,上下文的建模需要建立大規模的數據集。比如多輪對話和上下文理解。數據標注的時候要注意前后文。沒有這樣的數據,很難取得突破。
第二,強化學習很重要。我們需要根據用戶的反饋倒推模型并做參數修正,使模型更加優化。現在強化學習剛剛開始用在自然語言領域,性能并不穩定,但在未來很有機會。
第三,要引入常識和專業知識,并把這些知識構建好。這樣就能更加精準地回答問題。沒有人能證明現在常識知識用在語言問答和搜索中的作用有多大。所以,我們需要一個測試集來檢驗結果。這個測試集要專門測上下文和常識,可以讓我們要不停用新模型(比如強化學習或者知識圖譜)去試錯,來看系統性能能不能提升。
機器理解競賽究竟價值何在?
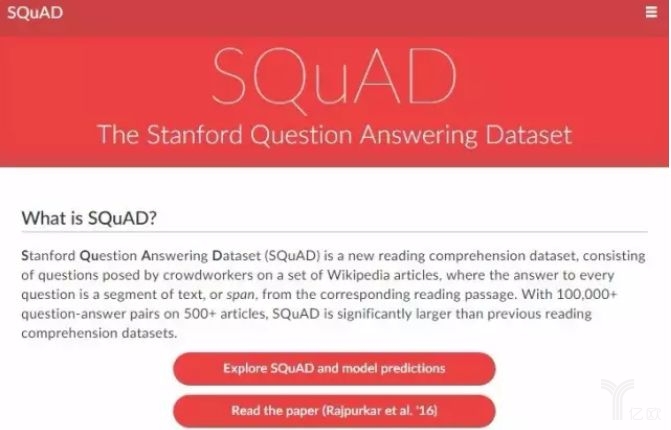
圖丨SQuAD的全稱是斯坦福問答數據集(Stanford Question Answering Dataset),是由斯坦福大學自然語言處理實驗室開發的數據集和比賽。SQuAD的數據來自Wikipedia的文章。數據標注人員去掉了文章里的一些單詞,并讓參賽隊伍利用模型重新填空,借以檢測模型對文章的理解程度
問:2017年,微軟亞洲研究院、阿里巴巴和哈工大·訊飛聯合實驗室分別宣布,自己開發的模型對文章的理解已經超過了人類標注員的水平,引起了很大的反響和爭議。類似 SQuAD 這樣的競賽是否有一些技巧刷分?類似的競賽對行業的意義有多大?我們需要什么樣的數據集和比賽?
Dan Roth :
這種競賽對于提高技術基礎建設會有一定的貢獻,但是長期來看,對推動科學研究和發展方面并沒有太多價值。
舉例來說,如果用相同數據集來進行競爭,持續個一年或兩年,比賽本身就會完全失去其意義。主要原因就是,如果人們只是為了競賽的數據來進行訓練,而不是我們所普遍關心的那些真正應該被解決的問題,那么,最后我們就不會看到真正的技術進展,而只剩為了拿到比賽名次而發展的各種小技巧。
周明 :
SQuAD的一些設置可以有效防止刷分。例如,數據集很大,而且測試集也沒有公布。總的來說,斯坦福的 SQuAD 可以說是自然語言處理領域一個里程碑式的創新。人們原來做閱讀理解,都是泛泛的去做,從來都不知道到底做到什么水平。但是,現在斯坦福做了一個大規模的,不太容易通過微調改進性能(fine tune)的數據集。實際上很有力地來促進這個領域。
但 SQuAD 確實存在問題。但正確的態度應該是巧妙地設計測試集的新難點,針對這些難點一條一條地把閱讀理解所涉及到的技術難點逐個攻關。久而久之,我們整體的閱讀理解能力就會循環往復地上升,最后就真的逼近人的平均水平。
例如,SQuAD 沒有涉及太多的推理能力,我們就可以做一個專門測試推理能力的測試集。推理還可以分幾級:簡單推理可以根據上文就能推理,復雜推理可以根據全文推理,更復雜的推理甚至必須要用到背景和領域知識。如果能把這樣一層一層的難度做出來的話,成功就有一半了。
未來研究的成功有兩個重要的因素,一個是模型,一個是可以用來評測競賽的數據集。















