
 登錄
登錄
 注冊
注冊
【詳解】如何避免大數據PaaS平臺建設中的這些“坑”?
現在一個企業或個人搞個hadoop集群不是難事,除非你想搞上千個節點,難得是如何才能用好這個平臺,因此,我們提出要建設一個PaaS平臺,讓操控數據的門檻足夠低,也只有大家都會用了,才有利于形成企業大數據應用的生態,從而更大程度的發揮出大數據的價值。
那么,何謂大數據PaaS?
運營商在進行全網BI系統規劃時,會頻繁遇到一個問題,各個省公司、各個部門都希望自己搭建大數據平臺,到處都缺少人才,甚至都在爭搶集成商的支持。隨著大數據技術的蓬勃發展,這個問題變得非常嚴重,關鍵在于沒有規模效益。公司能培養一百名大數據專家已經非常不容易了,但是如果分散在多個省,又分散在各個IT部門(如業務支撐、網管支撐和管理信息支撐系統),那么每個部門只能分到一個人。
所以很自然的想到“能否實現平臺和應用分離?”,可否統一搭建一個大數據平臺,然后各個單位在平臺上做分析模式、搭建自己的應用? 這種集中化的規劃,可能是業界第一次提出大數據能力開放平臺(PaaS)的概念。
大數據PaaS最重要的就是數據資源的管理,把它與大數據能力一樣看待,通通抽象成服務,即一切皆服務,從采集、存儲、計算、展現再到管理,下面一張圖道盡了一切,這里的DaaS是否可以算作PaaS呢?仁者見仁智者見智了,但如果從目的出發,筆者覺得可以算。

成就大數據PaaS的典范是阿里吧,你看他們的中臺,覆蓋了PaaS的方方面面,幾乎承載了所有數據平臺人員的夢想,以下來自《阿里巴巴大數據實踐之大數據之路》一書的描述。
數據采集層:
Aplus.JS+UserTrack雙劍合璧實現了Web和APP端的采集,TT實現了消息的傳輸,DataX實現了數據庫的同步。
數據計算層:
MaxConpute離線和StreamCompute實時是存儲和云計算平臺,讓其擁有了海量數據處理的底蘊。
數據整合和開發管理:
主要包括OneData和數據開發平臺,OneData就是數據倉庫建模,數據開發平臺就是提供各種開發測試工具,其中的D2(在云端)管開發及調度,SQLSCAN管SQL代碼質量,DQC管數據質量,在彼岸管測試,比如數據交換后的表、字段和分布一致性比對等等。
數據開放層:
使應用對底層數據存儲透明,將海量數據方便高效地對外開放,阿里叫OneService,主要提供數據查詢和實時數據推送服務。
當然,其實PaaS還包括了資源申請,數據賦權等功能,廣義來講就是以上的所有。
理解了大數據PaaS的價值,大家一定對PaaS非常神往,那么,對于一般企業如何打造這類企業級的PaaS平臺呢?
第一,自研,但大多時候是找死,當然簡單的搞個小工具也就無所謂PaaS了,筆者強調的是企業級,不是部門集市。
第二,全套外包,比如入駐阿里云,享受其提供的大數據PaaS服務,但將失去靈活性,數據安全隱患也成為很多企業不能承受之重。
第三,采購不同的PaaS組件,搭建符合企業自身特點的定制化大數據PaaS,這成為當前很多大型企業的選擇。
筆者重點談的是第三條道路,今天就從管理的視角來談談這種模式的一些挑戰,很多問題的根源其實不是技術問題,而是建設模式問題,你一旦選擇了模式三,就得有足夠的思想準備。
1、很難有合作伙伴能夠提供全套大數據PaaS組件,這意味著巨大的集成成本
這讓我想起了印度的LCA自研飛機,其外形參考法國幻影2000的,而其引擎系統則選用了美國通用提供的F404-GE-F2J3 發動機,另外還有俄羅斯負責參與測試的“卡韋里”渦輪風扇發動機,計算機系統也采用美國的產品,“阿瓊”坦克也是如此,其發展時間長達40多年,零配件基本都是進口,印度只是負責組裝,即使這樣,“阿瓊”的造價仍然高達接近1000萬美元,而且到目前為止,“阿瓊”仍然是一種發展中的坦克產品,它們是否能夠正常使用仍是未知數。
大數據PaaS也面臨同樣困境,其涉及的組件太多了,幾乎沒有任何合作伙伴能夠全套提供,比如數據計算用的是A產品,數據采集用的是B產品,數據開發用的是C產品,數據可視化用的是D產品,每一個產品單獨來看都挺不錯,但一旦湊一起要形成合力就充滿挑戰,別說1+1>2,能等于2已經挺不錯了,企業在獲得靈活性的同時,后續的運營成本很大,這里舉二個典型的挑戰:
(1)大數據統一的數據管理需要三方產品能按標準吐出元數據,由于各個產品開放程度不同,因此如果你希望能給予運維人員一致的使用體驗,能做端到端的影響或溯源分析,估計就很難了,協調的成本太高。
(2)建設大數據PaaS并不是一棍子買賣,后續各個組件都涉及到版本升級,這個時候往往牽一發而動全身,A產品要升級,B產品能否配合測試,C產品能否同步改造,全都是協調工作,而且產生了木桶效應,比如由于XX原因SPARK的版本長期停留在1.5版本,導致很多新功能不能用。
雖然該模式有很大的集成難度,但考慮到能集百家之長,因此成為了很多企業的首選,從大數據PaaS生態的角度看這是好事,但不建議合作伙伴搞什么全套大數據PaaS解決方案,這幾乎是不現實的,規劃與PPT可以寫得很好,但市場會給出答案。
大家說要向BAT看齊啊,它有的我也要有,但要知道阿里是有個阿里云托底的,PaaS組件也是基于阿里云生成,這樣PaaS產品的實施難度會直線下降,因此,阿里提OneService是相對容易的。
而大多合作伙伴的產品面對的是開放的生態,你底層要對接的是各種MPP,Hadoop,流處理組件等等,而且要跟著外面的生態與時俱進,因此開始的時候產品其實做不了那么精細,做透一個就相當不易。
比如阿里僅一個開發管理平臺就搞出了這么多輔助功能,什么DQC,SQLSCAN等等,我們到現在為止還沒實現呢,為什么?因為要做的事情太多了。
2、很難有合作伙伴能夠提供技術+體驗俱佳的大數據PaaS,而客戶這個“白老鼠”間接鑄就了他們的成功
為什么合作伙伴一開始很難提供技術+體驗俱佳的大數據PaaS?筆者認為根子在于以下兩點:
(1)合作伙伴縱然有強大的技術能力,但如果沒有足夠的數據,他們嘔心瀝血研發的杰作幾乎可以肯定是個半殘品,BAT在大數據方面的強大是因為他們的產品是基于自己的大數據慢慢孵化出來的,而大多數合作伙伴沒有這個機會,他們的PaaS是規劃出來的,模擬的海量數據場景跟真實的數據使用場景有很大的區別,他們的產品一開始非常不成熟。
比如A公司數據采集工具在剛交付客戶時,竟然沒有基本的統計功能,導致運維甚至無法評估到底有多少比例的接口在第一次上線時抽取失敗了,得一個個靠人去看,而這個客戶的接口有幾千個!
比如B公司在某個小省的客戶處順利升級了產品,但換到某個大省,就爆發了大規模的故障,原因就是大省的日志太多了,List不動了,然后各種超時。
比如C公司由于沒考慮到某個客戶數據庫中的字段中竟然會有文本逗號,這導致了異構數據庫間交換的失敗,極大影響了生產。
比如阿里的SQLSCAN估計是檢測SQL代碼質量的,這個功能很重要,可以避免SQL笛卡爾積啥的,但D公司的產品就是提供不了這個功能。
你看,合作伙伴縱有天才的程序員,總有想不到的數據問題和使用場景,而BAT依托于大數據的優勢讓其打造的產品生態具備天然的優勢,因此大家得抱團取暖,有數據差技術的,有技術沒數據的,來個優勢互補。
(2)呆在實驗室的那幫家伙幾乎不可能有機會接觸到客戶的一線維護人員的真實訴求,他們偏重開發更多的功能(意味著更多的收入),提供更強的性能(意味著碾壓競爭對手),但當我們欣喜的祝賀大數據PaaS平臺上線的時候,卻發現自己的一線維護人員要多花1小時去配置一個接口,這到底是怎樣一種體驗?
一般來講,B端的產品相對C端不是太強調體驗,但筆者覺得還是要具體問題具體分析,講不講體驗跟B端產品的性質和使用環境有關,具體可參考另一篇文章《為什么就做不好數據產品的體驗?》,大數據時代講究個機器換人,但突然發現需要更多的人去運作這臺機器的時候就感覺有點荒唐了,運營運維這種隱性成本其實很高。
A公司,B公司,C公司,D公司都非常拼命,現在的產品越來越好,這對整個大數據產業其實是好事,但也得感謝下那些第一個吃螃蟹的客戶,他們給予了海量數據的測試機會,抓出的BUG可謂汗牛充棟,讓這些公司的產品得以迭代演化。
如果你的企業需要建設大數據PaaS,但又不想吃螃蟹,那就不要太關注合作伙伴的PPT,應該直接問,在多少企業用過?多大的數據規模?現在有多少人在用?
3、很難有合作伙伴能夠兼顧到產品的短期和長期,新時期要在組織架構上進行變革
產品研發的集中化、標準化才能確保合作伙伴用最低的成本獲得最高的效益,合作伙伴對于大數據PaaS往往有自己的既定演進路徑,而客戶的需求往往在變,特別是大數據這種正處于從概念向實用的轉變中的業務,兩者之間的矛盾非常突出。
主要體現在以下三點:
(1)客戶提出的需求要進入合作伙伴的研發列表決策流程很長,動輒半年,很多合作伙伴提出要讓自己的專家聽得見一線的炮聲,但也是雷聲大雨點小。
(2)B端產品的商務決策流程很長,從客戶一線提出需求,到項目經理匯總,再到規劃部門,采購部門,信息耗損非常大,再加上合作伙伴的決策流程,到最后,一線的需求往往變了樣,一線作為使用人員在整個決策流程中其實是個弱勢群體。
(3)合作伙伴規劃的大數據PaaS產品功能跟具體的某個客戶的需求有出入,客戶并不愿意為自己不需要的功能買單,現在功能捆綁銷售的問題不少,合作伙伴該如何權衡?哪些該做,哪些不該做。
很多客戶受不了,只能另起爐灶,好一點的做法就是搞外掛,要求開放接口,自己搞小應用,不少合作伙伴拒絕開放接口,但這是下策,另一種就是選擇其他的替代品,有機會就顛覆你,由于B端產品問題的潛伏期比較長,很多合作伙伴往往渾然不知。
那么,有什么解決辦法呢?
筆者近期也在跟大數據PaaS合作伙伴探討解決方案,有兩個建議:
一是必須提升本地PSO的地位,一方面要承擔起一線需求對接的職責,并且擁有較強的開發能力,在研發短線支撐不了的時候,進行補位,甚至能承擔部分研發的職責,比如率先實現某些功能,另一方面也能傳遞真實的需求到研發,驅動大數據PaaS產品的成熟,成為感知客戶的”晴雨表”和雙方關系的”緩沖器”。
二是研發要走大中臺的路徑,主要做能力沉淀、前后端解耦及開放,為PSO賦能,讓其去滿足前端應用開發的要求,比如A公司的數據采集平臺雖然功能較多,但由于必須前臺配置,導致某些輕量級的抽取場景沒法用,A又不愿意開放能力,逼得客戶只能走外掛。
從這里我們似乎看到了阿里“大中臺,小前臺”的影子,是的,合作伙伴也可以借鑒這個理念,但不要僅僅局限在技術層面,阿里在實施這個戰略的時候,首先調整的是組織架構,如下圖:
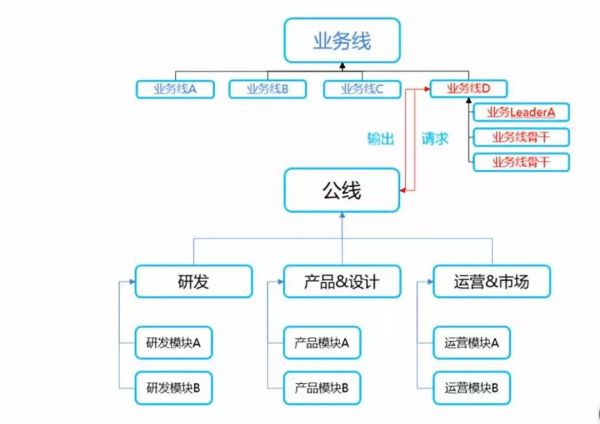
這是一個很有藝術的組織架構,但顯然當前大多公司的研發和PSO不是這種中臺和前臺的關系,研發只是單純的滿足需求,沒有中臺,無法開放能力,更無從談起敏捷響應,PSO更多是個配合角色,缺乏話語權。
布萊夫曼2016年出了本書《海星與蜘蛛》,說得就是去中心化的組織架構,集中的組織必須要放權,讓聽得見炮聲的基層組織進行指揮和戰斗,別老想著控制,這種手段越來越不好用了。















