登錄
登錄
 注冊
注冊
新零售浪潮下,人貨動作如何數字化?
業務分析
在“何時何地何人對何種商品發生了興趣?”這個問題中,時間地點上要求精準地確定顧客的行為發生在哪個時刻、位于門店內的哪個貨架附近;并要求準確的關聯顧客,甚至關聯上顧客的年齡、性別、新老客等屬性;以及要求準確地確定是哪個SKU的商品被翻動或者拿起。與自動售貨柜、線下大屏等場景不同,監控視角下相機離貨品過遠成像不清晰,同時商場和超市中的貨品排列密集成像不完整,因此視覺相機只能大體用于判斷顧客是否有翻動商品的動作,但是不能直接獲得“人-貨-場”中貨品的信息,如圖所示。

圖1. 顧客翻動商品快照
為了解決該問題,我們使用了目前在新零售場景中廣泛使用的無線射頻電子標簽(RFID),用于探測被用戶翻動的商品。被動RFID標簽價格低廉,可以廣泛裝配在服飾等貨物中。算法目前給出了“何時何地何人與何種商品發生交互”的數據,整體的實現流程如圖所示。
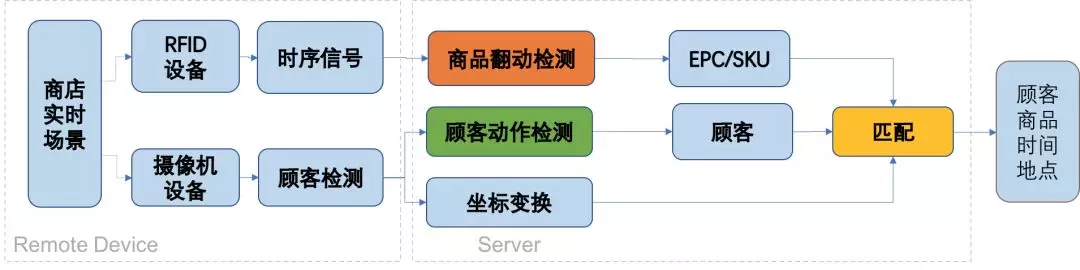
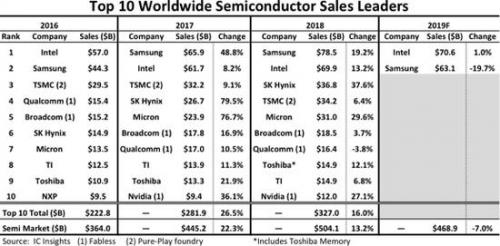
圖2. 人貨動作檢測整體技術框圖
其中,遠程實體店中裝配有監控攝像機設備與RFID接收器設備,分別錄制實時視頻與RFID標簽受激反射的時序信號;其中監控視頻通過在實體店中布署的遠端服務器運行顧客檢測算法得到有行人的圖片,只將檢測到的行人圖片回傳到后臺,RFID時序信號信號量較小因此全部回傳到后臺;后臺服務器環境中,首先基于回傳的RFID信號與檢測哪些RFID標簽可能被翻動了,由于店鋪服務員已經將RFID標簽的EPC編號與商品的SKU編號關聯入庫,基于被翻動的標簽EPC編號可以取到對應商品的SKU;同時,回傳的顧客圖片被送入Mobilenet分類器中進行分類,檢測出疑似有在翻動商品的顧客,并根據顧客的圖像坐標進行坐標變換,得到該顧客的真實物理坐標;最后,將檢測出的疑似被翻動的商品與疑似有翻動商品動作的顧客基于時間和動作的可疑程度進行關聯,得到商品與行人的最佳匹配,從而實現檢測“何時何地何人與何種商品發生交互”。
本文討論其中的三個關鍵的技術點:
基于圖像的顧客動作檢測算法;
基于射頻信號的商品翻動檢測算法;
基于二部圖匹配的人貨關聯算法。
1. 基于圖像的顧客動作檢測算法
基于圖像的顧客動作檢測算法隨著業務與布署的需求經歷了基于視頻檢測到基于單幀圖像檢測的演變過程。
1.1 視頻圖像動作檢測
1.1.1 問題分析
與行人、人臉檢測等問題不同,顧客與商品的交互動作是一個時序過程,例如“拿起”、“翻動”、“試穿”等都是有一定時長的時序過程,因此理解用戶的行為是一個典型的視頻動作分類問題。視頻級動作理解主要研究基于整段視頻進行模型學習與預測。隨著深度神經網絡的廣泛應用,視頻動作理解技術在近期得到了很大的發展,比較著名的有2014年的CNN模型[1]、2015年的LRCN模型[2]和2017年的I3D模型[3]。其中LRCN在單幀圖片上使用2D卷積提取特征,在幀與幀之間使用RNN提取時序關系,獲得了較好的效果但是訓練耗時巨大;I3D模型基于3D卷積真正實現對整個視頻進行特征提取,同時訓練速度加快了很多。
但是開源的數據集例如UCF101, HMDB51, Kinetics只有有限的幾類常見體育運動、樂器演奏活動等動作,并未包含商超場景下的數據。因此我們自主構造商超場景下的動作視頻,并提供給外包進行標注。商超場景下顧客與商品發生交互的過程是極其短暫的,在全天視頻中有顧客行為的的時段約只有0.4%,正例特別稀疏。為了盡可能發掘正例樣本,提高外包標注效率,我們使用Lucas–Kanade光流算法對視頻進行了預處理,通過初步判斷視頻中有無活動目標篩選視頻,經過該處理后,將樣本中正例的比例提高到了5%。為了提高樣本的置信度,我們同時還對樣本中的正例進行了校驗標定,確保正例的準確性。
1.1.2 動作檢測模型及其優化
為了檢測在視頻中發生的動作,本文嘗試了:
基于人體關鍵點檢測算法(Pose)與跟蹤算法(Track)自動裁剪得到每個顧客每只手的實時短視頻;
基于Inception-V1 C3D(I3D)模型訓練手部動作的分類器,并對I3D模型進行了裁剪優化。
裁剪顧客每只手的短視頻有助于精確確定動作發生的位置,同時由于顧客對商品的翻動動作一定是通過手部進行的,因此顧客身體的其他部位對檢測結果沒有直接影響,而關注于手腕局部有利于減小模型計算量、加快模型收斂,其中算法涉及的Pose模型基于Open Pose[4],Track算法基于Deep Sort[5],均有成熟的模型可以直接使用。
本文主要討論對Inception-V1 C3D模型應用于理解手部動作視頻的研究。基于圖片的學習任務通常使用2D卷積核在圖像上滑動并池化實現特征提取,而基于視頻的學習任務要求將傳統的2D卷積擴展到3D上,在視頻中滑動并池化實現特征提取。如圖所示,3D卷積相比于2D卷積多了一個時間維度。

圖3. 2D卷積池化與3D卷積池化操作示意圖
本文使用了新近提出的Inception-V1 C3D(I3D)模型,該模型將傳統的Inception-V1模型擴展到3D維度,在Kinetics, HMDB51, UCF101數據集上取得了目前最好的效果。I3D模型框圖如圖所示。示意圖中所有的卷積與池化操作都是3D層次上進行的,其中Mix模塊是Inception V1模型中的Inception感知子模塊,由4個branch構成,如右側所示。

圖4. I3D模型框圖(左)與Inception 子模塊結構
實際應用在商超顧客行為理解的任務中時,我們發現3D卷積帶來模型參數過多,極容易過擬合,同時網絡程度過深也導致模型泛化能力差,dropout作用微弱等問題,因此我們對Inception-V1模型作了簡化,去除了模型中不必要的多層Inception模塊(Mix_4c, Mix_4d, Mix_4e, Mix_4f, Mix_5c),并將每個Inception模塊的卷積核數量(depth)調少至原來的1/2,將模型簡化為如圖所示:
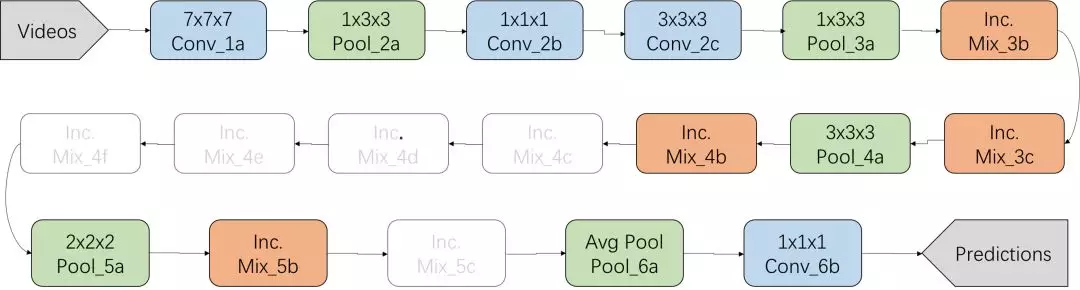
圖5. I3D模型的裁剪改進
該簡化操作將模型分類準確度(Accuracy)從80.5%提高到87.0%,進一步調試超參,最終分類Accuracy提高至92%.
1.1.3 結論與分析
我們將樣本使用tfrecords處理之后,上傳到了集團數據存儲中心,并使用PAI在分布式環境中進行了模型訓練(30張GPU卡),并將訓練所得的模型應用于理解顧客的動作,算法目前實現的實際預測效果如視頻動作檢測結果.mp4所示,目前在服務器下可以實現實時的對單路視頻中的顧客動作進行檢測,但是視頻動作分類檢測相比于傳統的圖像分類任務存在的問題主要有:
模型復雜度高,三維卷積(C3D, Convolutional 3D)需要同時在時間與空間上進行;
數據規模巨大,訓練困難,相比于圖片,視頻數據規模擴大了數百倍到數萬倍;
實際部署模型挑戰大,視頻動作模型在實用過程中的預測時間效率,組織時序樣本,滾動窗口預測等方面都存在極大的挑戰。
1.2 單幀圖像動作檢測
1.2.1 問題分析
基于視頻卷積的顧客動作檢測算法有較高的精度(92%), 并能給出準確的動作位置(精確到手腕位置),但是由于視頻3D卷積模型和Pose模型參數多復雜度高,一臺服務器只能跑一路檢測算法,給計算性能帶來沉重的負擔,同時三維卷積算法要求精準關聯一段時間以內的手部連續視頻,給Tracking算法也帶來很大挑戰。為了讓動作檢測算法可以適應于多路監控信號多個店鋪的場景中,我們進一步發展了基于單張圖片的可疑動作檢測算法,對單張圖片直接進行疑似動作的分類檢測。單張圖片的可疑動作檢測由于信息較少,準確性相對于基于視頻的動作檢測算法偏低,但是通過與RFID檢測結果相互融合校正,可以彌補其準確率較低的缺陷。
1.2.2 模型及其優化
基于單張圖片的疑似動作檢測是經典的二分類問題,為了減小對計算能力的需求,我們使用了MobileNet[6]作為分類模型。MobileNet是微軟提出的一種高效輕量的網絡模型,主要基于depth-wise convolutions和point-wise convolutions對傳統的卷積層進行了計算量上的優化。與傳統卷積網絡相比,MobileNet在保持精度幾乎不變的同時計算量和參數數量可以降到原來的10%~20%左右。本文中,使用了MobileNet_V1版本模型,并設置卷積通道數因子Depth multiplier為0.5以進一步減小模型規模。我們通過外包標注了圖片動作數據集,并對樣本作了均衡處理以保證訓練過程中正負樣本數量一致。同時,考慮到業務場景中希望盡可能捕捉到用戶有動作的瞬間,因此我們根據模型Logits輸出進行了最優化參數尋優,在保持分類精度(accu)89.0%左右時,提高正例召回率(recall)達到90%,確保正例盡可能被召回,如下圖所示。
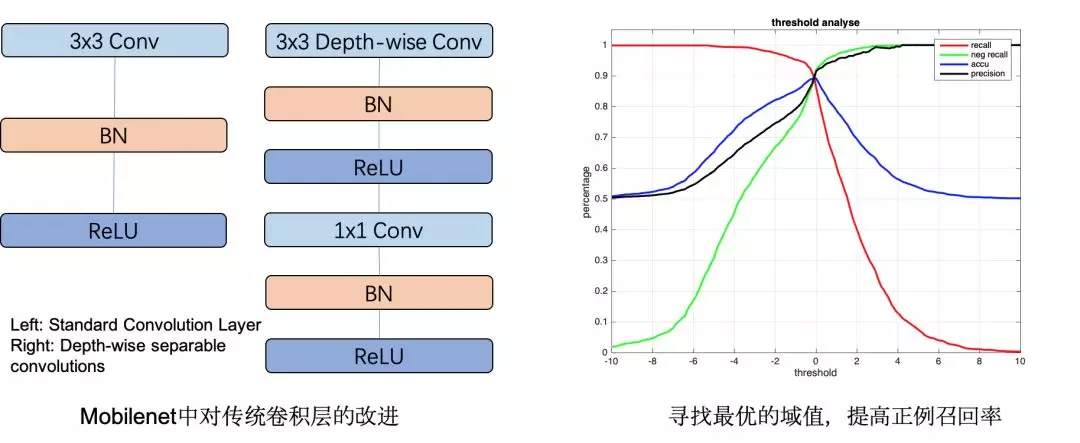
圖6. MobileNet模型優化
1.2.3 結論與擴展
基于圖片的動作檢測算法對動作的分類精度可達89%(略低于基于視頻的動作檢測算法,同時無法精確到手腕位置),召回90%。下圖展示了模型預測出的行人是否有拿取衣物的動作,其中圖片下方灰白色條紋表示模型檢測動作為正例,圖片下方黑色條紋表示模型檢測動作為負例。

圖7. 基于圖片的動作分類結果示例
由于基于圖片的動作檢測算法基于輕便的MobileNet模型,大大降低了計算復雜度,對一家門店全天的數萬張可疑圖片進行預測耗時只需要十分鐘左右。同時算法可以只對回傳到后端的圖像處理,大大降低了現場設備與服務器的負擔。但是基于圖片的動作檢測算法只精確到行人位置,不能給出精確的動作位置,同時同一個動作在前后若干秒內的圖片都有可能被檢測為正例,對時間關聯準確性也有一定影響。
2. 基于射頻信號的商品翻動檢測算法
2.1 問題分析
當顧客翻動衣服時,掛扣在衣服上的RFID標簽會隨之發生微小抖動,RFID接收機設備記錄標簽反射的信號RSSI,Phase等特征值的變化,回傳到后臺,算法通過對每個天線回傳的信號值進行分析判斷商品是否發生翻動。基于RFID信號判斷商品翻動存在諸多問題,包括信號自身噪聲、環境多徑效應、偶然電磁噪聲、貨柜對信號遮擋的影響等。同時RFID反射信號的大小與接收器離標簽距離遠近存在非線性關系[7],
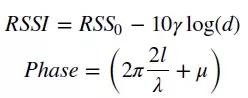
其中,d代表RFID標簽與接收器之間距離, l=d mod λ, γ受Multipath和當前環境的影響,μ表示各種靜態設備誤差帶來的偏移。從公式中可以看出,接收器安裝的位置,商店環境等都會給RFID信號帶來很大影響,尋找統一的可以適用于不同商店、不同位置接收器的翻動判斷算法存在很大挑戰。
2.2 翻動檢測算法及其優化
我們首先嘗試了建立監督模型檢測商品是否被翻動,通過收集門店中實際布署的兩個不同RFID天線采集的標簽RSSI與Phase時序信號,并手工組合了以下特征:

其中Ant1, Ant2表示兩個不同天線對同一個標簽采集到的信號,Diff表示對信號的差分運算,Avg表示對信號的均值處理。最終以每秒50幀,每個樣本采集8秒連續信號形成400×10的二維特征。并使用自主構造的數據集基于以下模型進行訓練,最終實際分類精度為91.9%。

圖8. RFID CNN模型
使用基于有監督模型的檢測算法可以獲得較高的商品翻動檢測精度,但是實際應用過程中發現模型泛化能力很差,當店鋪貨柜發生移動或者天線位置發生移動時,信號發生劇烈變化,基于原先數據集訓練好的模型很難泛化到新的場景中去。因此,我們進一步嘗試了基于無監督模型的算法,力圖提高檢測算法的泛化能力。特別的,我們注意到:相位信息與空間位置無關,但是與相對位移有關:相位信息頻率分布圖;頻率信息與空間位置無關,但是與動作快慢有關:頻域信息頻率分布圖。
嚴格意義上,頻率信息中的幅度信息與空間位置存在關系,但是當我們只關注于頻率分布(不同頻率成份的占比)時,可以將頻率信息也當成與空間位置信息無關的特征。頻率信息的獲取需要對RSSI信號與Phase信號進行離散傅利葉變換:
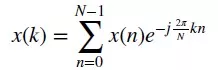
然后統計頻率信號與相位信號的分布圖。對得到的分布圖,計算當前分布與前一個時刻分布的JS散度(相對于KL散度,JS散度具有加法的對稱性,因此可以用來衡量多個分布之間的相對距離)。
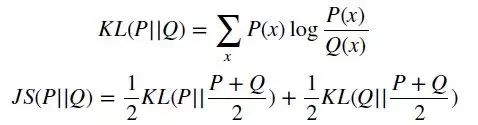
基于相鄰時刻前后兩個樣本的JS散差異對商品的翻動行為進行檢測,根據場景調節最終JS散度差異值域值可以得到與基于監督模型相近的動作檢測精度。
2.3 結論與分析
基于監督模型與無監督模型對商品的翻動情況進行了檢測,算法給出了精確的被翻動的商品(SKU),監督模型檢測精度可達91.9%,無監督模型的檢測精度可達94%(高于監督模型),同時使用JS散度度量提高了算法的泛化性能,根據不同場景輕微修正域值,檢測算法就可以適用于不同的場景。
3. 基于二部圖匹配的人貨關聯算法
3.1 問題分析
顯然,基于圖像的顧客行為檢測與基于RFID的商品翻動情況檢測是分離的兩個過程:
基于RFID的檢測給出了商品被翻動的情況,但是不能給出翻動動作對應的顧客;
基于圖片的動作檢測給出疑似在翻動商品的顧客,但是不能給出是哪些商品被翻動。
在實際場景中,同一位置同一時刻通常只有少數的幾個動作發生,因此可以根據RFID檢測出的商品被翻動的時刻和圖像檢測出的在翻動商品的顧客的時刻進行匹配,將翻動商品的顧客與被翻動的商品關聯起來。但是存在的問題是:
圖像檢測出的動作時刻與RFID檢測出的動作時刻累計誤差可達5~15秒。RFID信號、監控視頻信號回傳到服務端過程的傳輸時間差、現場設備時鐘不同步導致的時間差、算法估計動作時刻不準都會帶來兩種檢測算法的時刻不一致。
鄰近時刻鄰近位置可能有多個可疑顧客和多個可疑被翻動商品。
3.2 人貨關聯算法及其優化
我們對同一個貨架附近的RFID設備檢測出的動作與圖像檢測出的動作進行關聯,并在關聯動作時,同時考慮了時刻一致性與動作可疑程度的匹配性。確保同一貨架同一時刻確實有拿取商品的顧客關聯上確實被拿取的商品。當有多個顧客在同一個區域均有可疑動作或者多個商品在同一個區域均有可疑的被翻動情況時,進一步通過二部圖匹配算法,找到多個商品與多個顧客之間的最佳匹配。 本文中,顧客與商品的匹配程度(邊權)定義為:
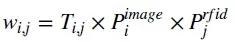
表示第i個顧客翻動第j個商品的可能程度,其中
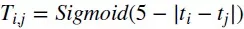
是基于Sigmoid函數描述的顧客與商品動作時間一致性函數,
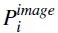
是MobileNet模型對輸入顧客圖片預測的動作概率,
是模型對輸入RFID信號預測的動作概率。最大化顧客與商品的匹配程度是一個帶權二部圖匹配問題,我們使用了的Hungarian[8]匹配算法對商品與顧客進行匹配,考慮到業務場景中顧客常常分批次進店購物(通常間隔十幾分鐘同時進店兩三個人),商品與顧客通常只在很短的幾分鐘時間內存在可能的匹配關系,該二部圖實際上由多個不連通的子圖構成(如圖所示):
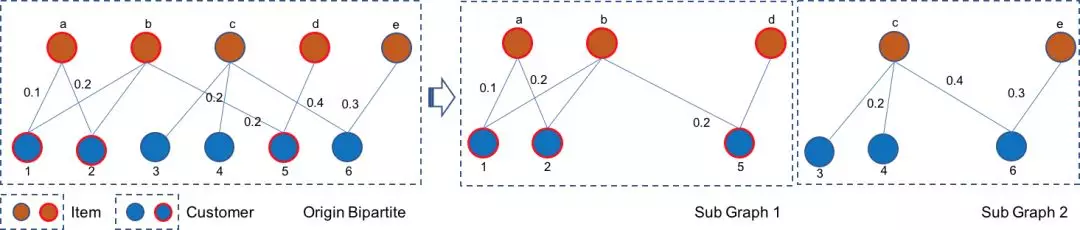
圖9. 人貨匹配的二部圖中存在多個子圖
因此我們在匹配算法之前先將二部圖分成了多個不連通的子圖,對每個子圖單獨進行匹配以降低計算與存儲復雜度。在使用鄰接矩陣存儲邊權關系時,分成子圖匹配大大提高了算法效率,將匹配全天數百至數千個顧客與商品所耗費時間從數個小時降低到了幾分鐘的量級。
3.3 結論與分析
基于二部圖匹配的人貨關聯算法可以得到商品與顧客之間的全天最佳匹配,改進后的算法大大提高了計算效率,將匹配全天顧客與行人耗費計算時間從數個小時降低到幾分鐘以內。同時,人貨關聯算法是整體人貨關聯的最終環節,人貨關聯的準確性受到顧客檢測準確性、基于單幀圖片檢測的顧客動作準確性(89%)、基于RFID的商品翻動行為檢測準確性(94%)以及人貨關聯匹配程度準確性等各個上游算法模型準確性的影響。
4. 結論與分析
我們整合了上述算法:
基于圖像的顧客動作檢測算法;
基于射頻信號的商品翻動檢測算法;
基于二部圖匹配的人貨關聯算法。
并在門店中進行實際預測。為了便于理解,這里給出了算法檢測出的若干示例結果:“何時(時刻)、何地(圖像坐標)、何人(行人ID)、與何種商品(商品SKU)發生交互”。
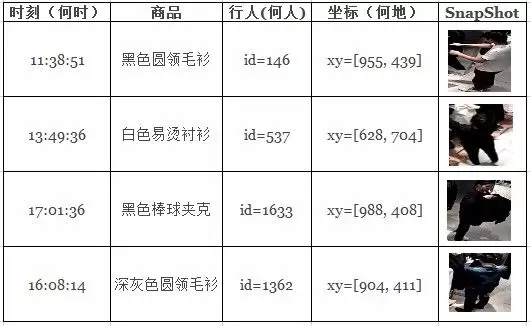
其中行人ID是顧客檢測算法為進店用戶賦予的編號,坐標這里給出的是圖像中的坐標,并在下游流程中可以變換至其在店鋪中的物理位置,SnapShot是算法匹配上的顧客在翻動商品的瞬間。
基于單幀圖片的動作檢測盡管精度偏低,但是對提高顧客與商品的關聯準確性卻有明顯的作用。我們對比分析了不作單幀圖片動作檢測關聯得到的人貨數據與基于單幀圖片動作檢測關聯得到的人貨數據,發現基于單幀圖片的動作檢測算法將匹配的最終準確率從40.6%提高到了85.8%。
由于人貨關聯算法是整體人貨關聯的最終環節,人貨關聯的準確性受到各個上游算法模型準確性的影響,我們通過時間關聯程度與動作可疑程度兩個維度同時進行匹配,使得最終的匹配行人與翻動商品的準確率可以達到85.8%。說明了:
人貨場精細到商品SKU與行人動作秒級的關聯是切實可行的;
基于無監督的RFID檢測算法可以降低規模化部署商品翻動檢測算法的難度;
基于單幀圖片的行人動作檢測算法切實有效并可以直接在后端服務器環境規模化布署;
同時,算法目前仍處于初級階段,在以下若干個方向中仍需進一步化化擴展:
1.基于單幀圖片的行人動作檢測算法仍有很大的優化空間:數據集從千張正例提升到數萬張正例可能可以帶來顯著性能提升,服務器可以承受更多的計算壓力,因此分類模型可以嘗試VGG, ResNet, Inception等更優的模型。
2.目前的單幀圖片動作檢測算法位置上只精確到行人位置,可以嘗試檢測模型將定位精度精確到動作發生位置。
3.目前RFID接收器只能檢測附近1~3米內幾十個商品到幾百個商品的信號,同時RFID接收器的采集頻率,天線輪詢機制對RFID檢測的容量與范圍帶來很大限制。RFID檢測算法從硬件層開始優化可以實現大大降低成本并提升檢測容量、范圍與精度。
4.無監督的RFID商品翻動檢測算法依賴域值調試,尋找可以泛化到不同門店的無監督檢測算法仍然有很大優化空間。
5.關聯人貨目前基于時間與動作可疑程度,進一步可以依據粗略的商品位置與行人位置進行關聯,對于提高關聯準確率將會有較大作用。