
 登錄
登錄
 注冊
注冊
基于時隙的RFID防碰撞算法分析
無線射頻識別技術( RFID) 是一種非接觸的自動識別技術, 因其具有識別距離遠、穿透能力強、多物體識別、抗污染等優點, 現已廣泛應用于工業自動化、商業自動化、交通運輸控制管理、產品證件防偽、防盜等眾多領域, 成為當前IT 業研究的熱點技術之一。
RFID 系統一般由標簽(Tag)和讀寫器(Reader)兩個部分組成。在系統工作時, 當有多個標簽同時發送數據時就會出現碰撞, 其結果會導致傳輸失敗。因此需制定適當的防碰撞算法, 避免或減少碰撞, 從而有效地提高系統性能。一般防碰撞算法可以分為隨機型和決定型。本文主要研究隨機防碰撞算法中常見的兩類算法: 幀時隙ALOHA 算法及其改進型的、時隙隨機算法。
1 幀時隙ALOHA 算法
在RFID 系統中, 幀時隙ALOHA 算法的“幀”是由讀寫器定義的一段時間長度, 其中包含若干時隙。時隙指標簽收到讀寫器命令后, 發送標識的時間長度。標簽被隨機分配到一個時隙應答, 當一個時隙中分配到多個標簽時就產生碰撞。根據幀內時隙數是否變化分為固定幀時隙ALOHA 算法和動態幀時隙ALOHA 算法。
1 .1 固定幀時隙ALOHA 算法
固定幀時隙ALOHA( FFSA) 算法是最基本的一種算法, 每幀時隙數的大小都一樣。識別過程開始時, 由讀寫器向識別場內所有標簽發送一個包含時隙數L 的命令。這些標簽收到命令后, 將其時隙計數器復位為1, 開始記錄時隙數, 同時從1~L 中選擇一個數做為其時隙數值。當時隙計數器值與標簽隨機選擇的時隙數值相同時, 標簽向讀寫器發出應答信息。若標簽被讀寫器成功識別, 則退出識別系統。一個幀完成后, 讀寫器開始時隙數同樣為L 的新幀。
FFSA 算法設計簡單, 但缺點是如果標簽數遠遠多于固定的時隙數, 會產生過多碰撞; 反之, 會產生較多空閑時隙, 造成資源浪費。只有在標簽數與時隙數差不多的一段時間內, 系統吞吐率最大。可見, 由于FFSA 算法的時隙數不能隨著標簽數而變化, 系統無法獲得穩定的吞吐率。為改善這一缺點, 提出一種改進算法——— 動態幀時隙ALOHA 算法。
1 .2 動態幀時隙ALOHA 算法
動態幀時隙ALOHA( DFSA) 算法是每幀時隙數都會根據標簽數的不同而變化。為獲得系統最大吞吐率,DFSA 算法需要在識別過程中估算標簽數, 用以確定匹配時隙數。在標簽總數未知的情況下, 當初始時隙數L<16 時, 第一次讀取過程通常不能識別出標簽。因此為節約初始時間, 設置初始時隙數Linit=16[1]。標簽估算的方法有很多種[2- 4] , 例如:
(1)估算出參與識別的標簽總數。設時隙數為L, 標簽數為n, 則一個幀中碰撞時隙率Cratio=1- (1- 1L)n (1+nL- 1)[2]。在讀寫器識別過程中, 已知當前幀時隙數為L, 并且可以統計出該幀時隙碰撞率Cratio, 采用逼近算法, 可以估算出n。
( 2) 直接估算出未識別的標簽數。當系統達到最大吞吐率時, 一個時隙的碰撞率Ctags=0.418 0[2], 因此一個時
隙碰撞的標簽數Ctags= 1 Crate=2.392 2[2]。讀寫器在識別過程中, 統計前一個幀的時隙碰撞數Ncoll , 則未識別標簽數nest=2.392 2×Ncoll。得到未識別標簽估計數nest 后, 從理論上講最優的時隙數L 應該等于nest[2] , 但在實際應用中, 讀寫器能夠設定的時隙數是定值, 通常為1, 8, 16, 32, 64, 128, 256。
因此, 讀寫器需要根據nest 從以上幾個數中選擇一個數作為下一幀的時隙數。對250 個以內不同數目的標簽,選擇不同時隙數, 計算一個幀的吞吐率。對不同標簽數選擇吞吐率最大所對應的時隙數如圖1 所示, 得到標簽數與匹配時隙數的對應關系如表1 所示。樣就可以在估算出未識別標簽數之后, 在下一幀中選擇匹配的時隙數, 從而提高系統吞吐率。
1 .3 帶延遲的幀時隙ALOHA 算法
幀時隙ALOHA 算法中, 若幀時隙數遠遠小于標簽數, 在匹配前系統吞吐率很低。為了在時隙數與標簽數匹配前, 提高當前幀的吞吐率, 引入了延遲機制, 即當標簽隨機選擇的時隙數與時隙計數器數值相同時, 標簽并不立即應答讀寫器, 而是延遲若干時隙( 從0~7 的范圍內選擇) 后再發出應答信息[5]。

表1 時隙數與標簽數的對應關系
|
L |
nest |
|
1 |
0~1 |
|
8 |
2~11 |
|
16 |
12~22 |
|
32 |
23~45 |
|
64 |
46~89 |
|
128 |
90~176 |
|
256 |
>176 |
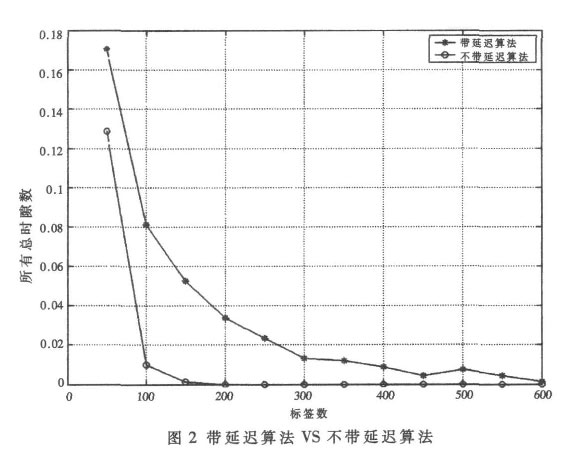
圖2 是設定初始時隙為16, 對比不同標簽數( 標簽數大于16) 下第一個幀的吞吐率。由圖2 看出, 帶延遲的算法的確可以提高一幀的吞吐率, 然而延遲算法只有在標簽數多而時隙數少的情況下才有利于提高系統吞吐率。在相反的情況下, 延遲算法在減少碰撞時隙的同時, 產生過多的空閑時隙, 不能提高系統的吞吐率。
1 .4 分組幀時隙ALOHA 算法
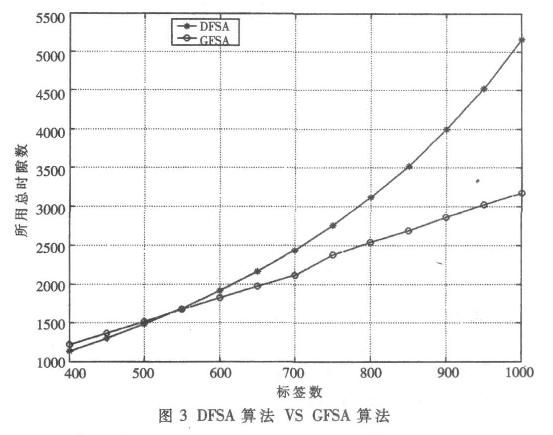
幀時隙ALOHA 算法局限于每幀最大時隙數為256。當標簽數遠遠大于256 時, 系統無法通過增大時隙數來提高吞吐率。為解決這個問題, 在DFSA 算法的基礎上提出分組幀時隙ALOHA 算法( GFSA) 。參考文獻[3]中說明, 當標簽數多于354 時將全部標簽分成兩組或者更多組, 讀寫器分別對每組標簽進行識別, 從而可以很好地提高系統的吞吐率。圖3 為普通DFSA 算法與分組GFSA 算法在標簽數多于400 時識別所用的總時隙數的比較, 初始時隙設為256。圖3 的結果表明, 標簽數越多, 分組算法GFSA 的優越性越明顯。但是這種算法需要在原有的DFSA 算法上做很多修改, 例如讀寫器命令需要加入分組參數, 標簽需要確定并保存自己的分組序號, 這使得實現變得有些困難。
2 時隙隨機算法( SR)
時隙隨機算法沒有幀的概念, 取而代之的是識別周期。識別周期是指讀寫器兩次發送開始識別命令( Query) 的時間間隔。SR 算法同樣是令標簽選擇時隙應答, 但區別在于, 幀時隙ALOHA 算法在一個幀所有時隙完成之后才能更改時隙數, 使未識別標簽重新選擇時隙; 而SR 算法在一個識別周期內可以隨時更改時隙數,讓未識別標簽重新選擇, 實現了時隙數的自適應過程。以ISO/IEC 18000 - 6 Type C[5] 為例, 識別過程由讀寫器發送Query 命令開始, 命令包含時隙參數Q。標簽從0~2Q- 1 范圍內隨機選擇一個數作為自己的槽計數器值。當槽計數器值等于0 時, 標簽應答。若標簽被讀寫器成功識別, 則退出識別系統。
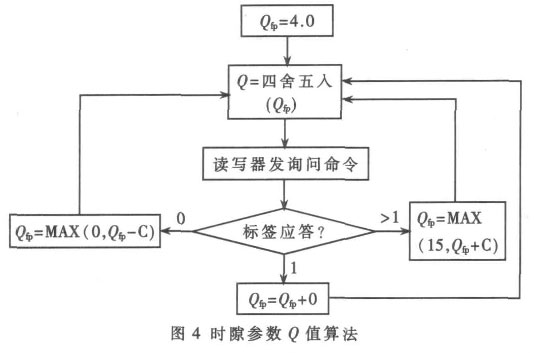
讀寫器通過發送開始下一個時隙的命令( QueryRep) , 令標簽的槽計數器值減1, 若槽計數器值為0(前一個時隙碰撞的標簽), 則將其記為最大值(7FFFh)。當讀寫器認為需要更改時隙數時, 發送更改時隙參數的命令(QueryAdjust), 令原有Q 值加1 或減1, 這時標簽會重新產生槽計數器值。時隙數的自適應過程是通過發送QueryAdjust 命令實現的。讀寫器根據幾個時隙的識別情況( 而非一個周期) , 增加或減少時隙參數Q, 使之能夠及時有效地反映標簽數的動態變化。一種簡單的Q 值算法是在讀寫器中設計一個參數Qfp 作為Q 的浮點數。每次讀寫器都根據標簽的應答情況更改Qfp 值, 然后將Qfp 四舍五入為一個整數值。若這個整數不同于之前的Q 值, 則讀寫器發送QueryAdjust 命令, 令Q 等于這個整數; 否則讀寫器不
改變Q 值, 發送QueryRep 命令。其過程如圖4 所示。其中C 為Qfp 的變化步長。一般來說, Q 與C 成反比, 因此
可以取C=0.8/Q [6]。初始時隙數與DFSA 算法相同, 取16, 即Q=4。
3 仿真分析
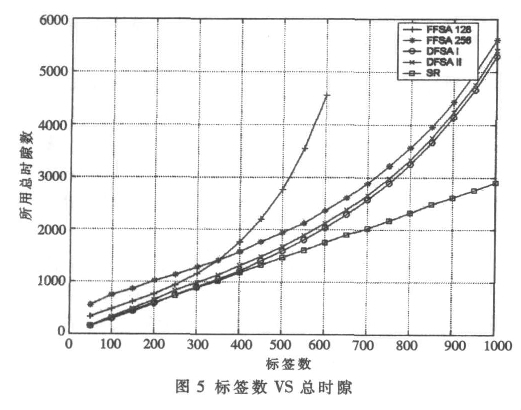
圖5、圖6 分別描述了識別一定數目的標簽所需要的總時隙數和系統吞吐率。圖中, FFSA 128 和FFSA 256分別代表采用128 和256 時隙數的固定幀時隙ALOHA算法; DFSA I 和DFSA II 分別代表采用1.2 節第一種標簽估計算法和第二種標簽估計算法的動態幀時隙ALOHA 算法; SR 算法代表時隙隨機算法, 其Q 值算法采用第2 節所述方法。
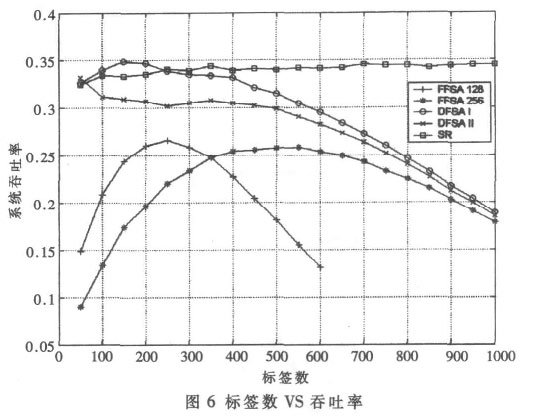
從圖5、圖6 中可以看出, 若采用時隙數為128 的FFSA 算法, 當標簽數超過300 時, 識別標簽所需的時隙總數迅速增長。同樣采用時隙數為256 的FFSA 算法, 時隙總數也呈現迅速增長的趨勢。FFSA 算法的系統吞吐率較低而且吞吐性能不穩定。若采用DFSA 算法, 識別標簽所需的時隙總數略有下降。當標簽數少于600 時, 系統吞吐率較高而且相對穩定; 當標簽數大于600 時, 由于受到最大時隙數256的限制, 系統吞吐率開始下降。此時可以通過GFSA 算法提高系統吞吐率。仿真中采用兩種不同估算標簽算法的DFSA 算法, 其性能差不多。但從實現角度講, DFSA II算法更好一些, 因為它容易實現。
SR 算法作為另外一類基于時隙的防碰撞算法, 其性能遠遠優于前面幾種算法。SR 算法采用時隙數自適應機制, 不僅減少碰撞時隙和空閑時隙產生, 而且使碰撞標簽可以及時重新參與識別。SR 算法的最大時隙數可達215 , 在實際應用中, 即便識別很大數量的標簽時,也不會受到時隙數的限制。采用SR 算法系統吞吐率最高且保持在一個定值左右。特別在識別很大數量的標簽時, SR 算法識別標簽所用的總時隙數比DFSA 算法減少很多。
總之, 在RFID 系統中, 基于時隙的防碰撞算法關心的首要問題都是使時隙數與標簽數相匹配, 這樣才能提高系統吞吐率。對于文中分析的兩類算法, 幀時隙ALOHA 算法設計簡單, 適合于識別數量在600 個以內的標簽; 時隙隨機算法相對復雜一些, 但系統吞吐率高而且性能穩定, 特別適合識別很大數量的標簽。
參考文獻
[1] 吳晶, 熊璋, 王曄. 利用動態時間槽分配的多目標防沖突射頻識別. 北京航空航天大學學報, 2005 , 31(6).
[2] CHA J R, KIM J H. Novel anti- collision algorithms forfast object identification in RFID System. The 11th InternationalConference on Parallel and Distributed Systems,2005.
[3] LEE S R, JOO S D, LEE C W. An enhanced dynamicframed slotted ALOHA algorithm for RFID tag identification.The Second Annual International Conference on Mobile and Ubiquitous Systems: Networking and Services, 2005.
[4] VOGT H. Multiple object identification with passive RFID tags. Department of Computer Science Swiss Federal Institute of Technology.2002.
[5] ISO/IEC 18000- 6.
[6] CHRISTIAN F, MATTHIAS W. Comparison of transmission schemes for framed ALOHA based RFID protocols.
The International Symposium on Applications and the Internet Workshops, 2005.













