
 登錄
登錄
 注冊
注冊
物聯網:數據淘金——從數據中挖掘有效信息
如今是信息時代,得數據者得天下。然而,只是“有”數據還不夠,數據的“準確性”和數據的“分析”也是至關重要的。愛因斯坦也說過:“能用的不一定有用,有用的也不一定能用。”
“數據”和“信息”不是一碼事。“數據”說的是一堆未經處理的原始測量結果,我們要分析它,取其精華去其糟粕,以用于獲得有用的信息。所以咱們常說的“信息過載”其實不對,“數據”可能會過載,但“信息”越多越好。數據本身不一定有用,因為如果沒有經過適當的篩選,數據可能像假新聞一樣,使我們誤入歧途。
過去十年間,我們的數據量實現了爆炸式增長。《紐約時報》報道,2005年全球數據總量達到1300億GB。現在的公司經常要處理數以PB記的數據。隨著數據源的飛速增長,數據的獲取速度也越來越快。科技進步如此迅速,轉眼已是滄海桑田。據@HistoricalPics推特所述,1956年一個5MB硬盤要超過2000磅重,IBM要用一架飛機才能運輸!低頭看看巴掌大的手機,不由得心生感慨。

隨著對人們活動和傳感器的測量,數據類型也在不斷增加。而我們要記住:數據,只有經過了分析,變成了信息才有用。
物聯網的優勢在于它能實時獲取、組織數據。如果架構正確,物聯網可以把數據變成有用的信息,用來決定下一步怎么辦。
Kristian J. Hammond在《哈佛商業評論》中曾擲地有聲地說:“大多數時候,我們都知道我們想從數據中得到什么:我們知道需要分析什么東西、需要尋找什么相關性、需要怎么比較。我們可以把數據交給一個可以勝任這些工作的機器,然后讓它用人類的方式、用自然語言告訴我們結果。這樣,我們就能穩定、迅速地從數據中提取到大量有用信息——但如今還沒有實現。通過輔以機器的力量,我們可以全自動地從數據中淘金,讓冰冷的數字變成感性的認知。“
如何發現數據的內涵?
物聯網之前,分析傳感器各式各樣的海量數據非常困難。通過物聯網技術,我們可以把機器得到的數據放入數據池自動分析,以決定下一步需要對數據和程序做些什么。物聯網不僅收集、分析數據,它還會自我提升。
在介紹具體步驟前,我們先明確兩個在討論數據傳輸時常用的術語:“北向(northbound)”和“南向(southbound)”。“北向數據”是指從設備發出,通過網關,送至云端的數據,一般是遙測數據,也可能是命令和控制請求。“南向數據”則是從云發至網關,或者從云通過網關發至設備,一般是命令和控制信息(如軟件的更新,請求、更改配置參數等)。
以下是利用南、北行信道,從探測數據中找到有用信息的方法:
第一步 :傳感器發出北向遙測數據。根據架構的不同,這些數據會被預處理,然后發送到位于傳感器附近的數據存儲器(比如一個網關)。
第二步 :在網關這個臨時節點上對數據進行一定量的分析,你可以在這處理數據(例如匯總數據,或者轉換數據,為數據中心或云深入分析做好準備)。然后,把在網關上處理的信息和之前的精確結果比對,就是在歷史信息中進行相關性匹配。發現的模式可以作為我們行動的依據。但除了發現已知模式,你也想找到你不知道的東西,想發現新的相關性和結論。例如,你可能不知道當氣溫降到10℃以下時,醫生開出的抗流感處方會增加30%,而同時雞湯、紙巾的銷售額也會10天內上升。你以前可能沒注意到這些關聯,但現在有了物聯網,你就可以用這些做出新的商業決策。
第三步 :利用新的信息,您就可以建立一個規則。例如,當傳感器發現溫度已經降到10℃以下時,就讓倉庫把雞湯和紙巾運到碼頭附近。這樣,你就把信息變成了可監控、管理、執行的行事規則。
第四步 :最后把制定好的規則付諸實踐。就是如圖所示的迭代過程。
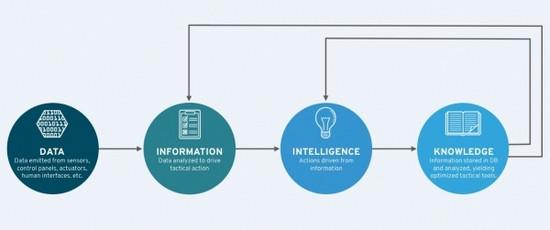
開源何益?
開源軟件項目提供了標準化的工具包(例如Camel、Drools),你可以用它處理、操作數據。Apache Camel是一種基于Java規則的路由和中介引擎,具有可以處理數據的企業集成模式。它通過“開箱即用”(out-of-the-box)的信息中介、路由、數據轉換,可以聯網解決方案的開發。我認為最好通過Eclipse IoT工作組項目(如Eclipse Kapua、Kura)在IoT中使用Apache Camel。
JBoss社區的Drools是一個內置了規則模板的業務規則管理系統,你可以用它規定在什么情況下應該采取什么措施。Drools通過定義明確的DSL(域特定語言)來實現物聯網所需的規則和優化規則引擎所需的可擴展性。它還附帶一個名為Workbench的GUI,可以讓開發者非常簡單地創建、編輯規則。
把數據轉化為有用的信息是所有物聯網工作的核心,而通過開源軟件可以實現這一目標,這有助于加速將物聯網付諸實踐。
















